为什么要克隆?
- new出来的对象的属性都是初始化时候的值,当需要一个新的对象来保存当前状态的对象就要靠clone方法。
- 把这个对象的临时属性一个一个的赋值给我新new的对象可以是可以,但是一是麻烦,二是,通过源码发现clone是一个native方法,在底层实现,速度快。
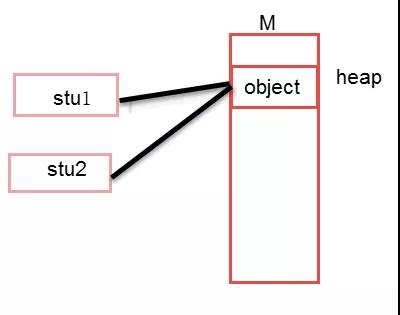
注意:我们常见的Object a = new Object(); Object b = a;这种形式的代码复制的是引用,即对象在内存中的地址,a和b对象仍然指向了同一个对象。而通过clone方法赋值的对象跟原来的对象是同时独立存在的。
如何实现克隆
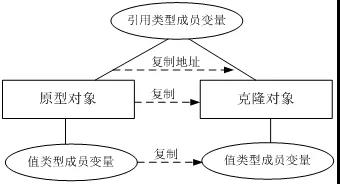
在Java语言中,数据类型分为值类型(基本数据类型)和引用类型,值类型包括int、double、byte、boolean、char等简单数据类型,引用类型包括类、接口、数组等复杂类型。浅克隆和深克隆的主要区别在于是否支持引用类型的成员变量的复制,下面将对两者进行详细介绍。
浅克隆(ShallowClone)
在浅克隆中,当对象被复制时只复制它本身和其中包含的值类型的成员变量,而引用类型的成员对象并没有复制。
- 被复制的类需要实现Clonenable接口(不实现的话在调用clone方法会抛出CloneNotSupportedException异常), 该接口为标记接口(不含任何方法)
- 覆盖clone()方法,访问修饰符设为public。方法中调用super.clone()方法得到需要的复制对象。(native为本地方法)
1 | class Student implements Cloneable{ |
深克隆(DeepClone)
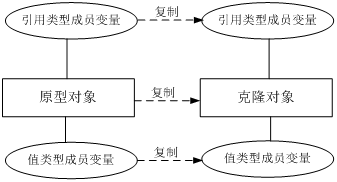
在深克隆中,除了对象本身被复制外,对象所包含的所有成员变量也将复制。
1 | class Address implements Cloneable { |
java.util.Date该类其实也属于深度复制:
1 | /** |
在Java语言中,如果需要实现深克隆,可以通过覆盖Object类的clone()方法实现,也可以通过序列化(Serialization)等方式来实现。
多层克隆问题
如果引用类型里面还包含很多引用类型,或者内层引用类型的类里面又包含引用类型,使用clone方法就会很麻烦。这时我们可以用序列化的方式来实现对象的深克隆。
序列化就是将对象写到流的过程,写到流中的对象是原有对象的一个拷贝,而原对象仍然存在于内存中。通过序列化实现的拷贝不仅可以复制对象本身,而且可以复制其引用的成员对象,因此通过序列化将对象写到一个流中,再从流里将其读出来,可以实现深克隆。需要注意的是能够实现序列化的对象其类必须实现Serializable接口,否则无法实现序列化操作。
1 | public class Outer implements Serializable{ |
Inner也必须实现Serializable,否则无法序列化:
1 | public class Inner implements Serializable{ |
这样也能使两个对象在内存空间内完全独立存在,互不影响对方的值。
总结
实现对象克隆有两种方式:
- 实现Cloneable接口并重写Object类中的clone()方法;
- 实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆。
拓展
- Cloneable接口和Serializable接口,它们都是空接口,这种空接口也称为标识接口,标识接口中没有任何方法的定义,其作用是告诉JRE这些接口的实现类是否具有某个功能,如是否支持克隆、是否支持序列化等。
- 基于序列化和反序列化实现的克隆不仅仅是深度克隆,更重要的是通过泛型限定,可以检查出要克隆的对象是否支持序列化,这项检查是编译器完成的,不是在运行时抛出异常,这种是方案明显优于使用Object类的clone方法克隆对象。让问题在编译的时候暴露出来总是优于把问题留到运行时。