常用关键字
volatile和synchronized
关键字volatile可以用来修饰字段(成员变量),就是告知程序任何对该变量的访问均需要从共享内存中获取,而对它的改变必须同步刷新回共享内存,它能保证所有线程对变量访问的可见性。但是不必过多使用volatile,因为它会降低程序执行的效率。
关键字synchronized可以修饰方法或者以同步块的形式来进行使用,它主要确保多个线程在同一个时刻,只能有一个线程处于方法或者同步块中,它保证了线程对变量访问的可见性和排他性。
如下使用了同步块和同步方法,通过使用javap工具查看生成的class文件信息来分析synchronized关键字的实现细节:
1 | public class Synchronized { |
在Synchronized.class同级目录执行javap –v Synchronized.class,部分相关输出如下:
1 | public static void main(java.lang.String[]); |
上面class信息中,对于同步块的实现使用了monitorenter和monitorexit指令,而同步方法则是依靠方法修饰符上的ACC_SYNCHRONIZED来完成的。无论采用哪种方式,其本质是对一个对象的监视器(monitor)进行获取,而这个获取过程是排他的,也就是同一时刻只能有一个线程获取到由synchronized所保护对象的监视器。
任意一个对象都拥有自己的监视器,当这个对象由同步块或者这个对象的同步方法调用时,执行方法的线程必须先获取到该对象的监视器才能进入同步块或者同步方法,而没有获取到监视器(执行该方法)的线程将会被阻塞在同步块和同步方法的入口处,进入BLOCKED状态。
下图描述了对象、对象的监视器、同步队列和执行线程之间的关系。
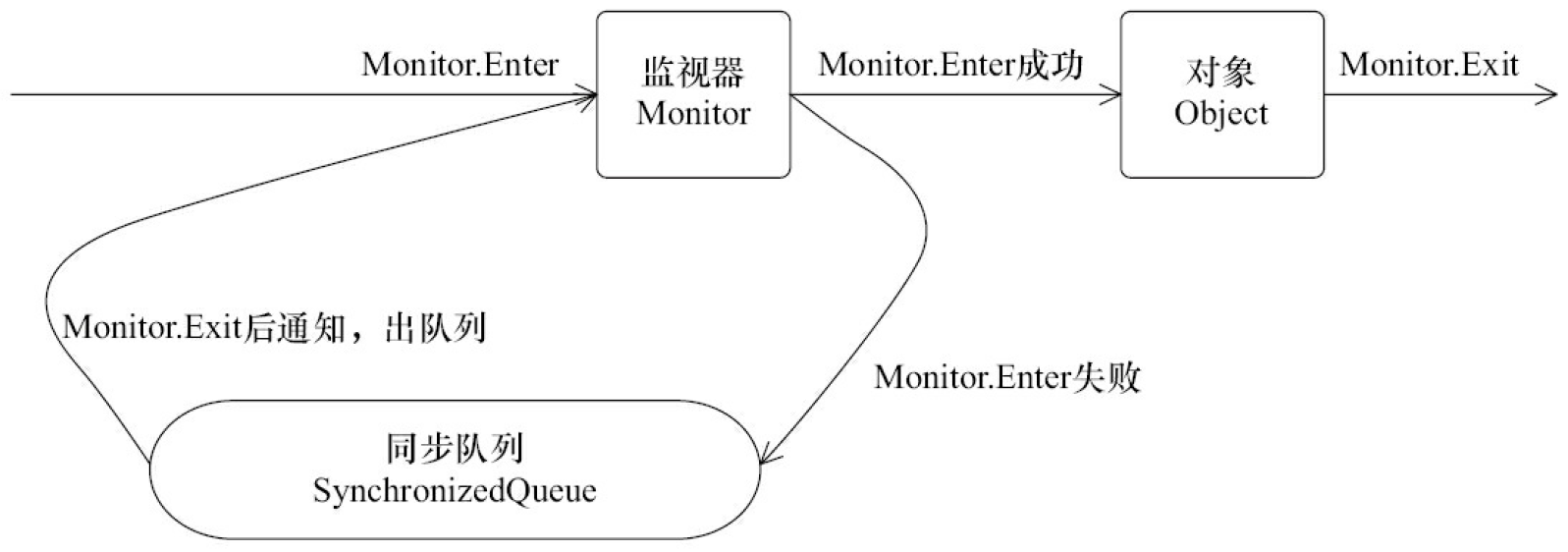
从上图可以看到,任意线程对Object(Object由synchronized保护)的访问,首先要获得Object的监视器。如果获取失败,线程进入同步队列,线程状态变为BLOCKED。当访问Object的前驱(获得了锁的线程)释放了锁,则该释放操作唤醒阻塞在同步队列中的线程,使其重新尝试对监视器的获取。
等待/通知机制
一个线程修改了一个对象的值,而另一个线程感知到了变化,然后进行相应的操作,整个过程开始于一个线程,而最终执行又是另一个线程。
前者是生产者,后者就是消费者,这种模式隔离了“做什么”(what)和“怎么做”(How),在功能层面上实现了解耦,体系结构上具备了良好的伸缩性,但是在Java语言中如何实现类似的功能呢?
简单的办法是让消费者线程不断地循环检查变量是否符合预期,如下代码所示,在while循环中设置不满足的条件,如果条件满足则退出while循环,从而完成消费者的工作。
1 | while (value != desire) { |
上面这段伪代码在条件不满足时就睡眠一段时间,这样做的目的是防止过快的“无效”尝试,这种方式看似能够解实现所需的功能,但是却存在如下问题:
- 难以确保及时性。在睡眠时,基本不消耗处理器资源,但是如果睡得过久,就不能及时发现条件已经变化,也就是及时性难以保证。
- 难以降低开销。如果降低睡眠的时间,比如休眠1毫秒,这样消费者能更加迅速地发现条件变化,但是却可能消耗更多的处理器资源,造成了无端的浪费。
以上两个问题,看似矛盾难以调和,但是Java通过内置的等待/通知机制能够很好地解决这个矛盾并实现所需的功能。
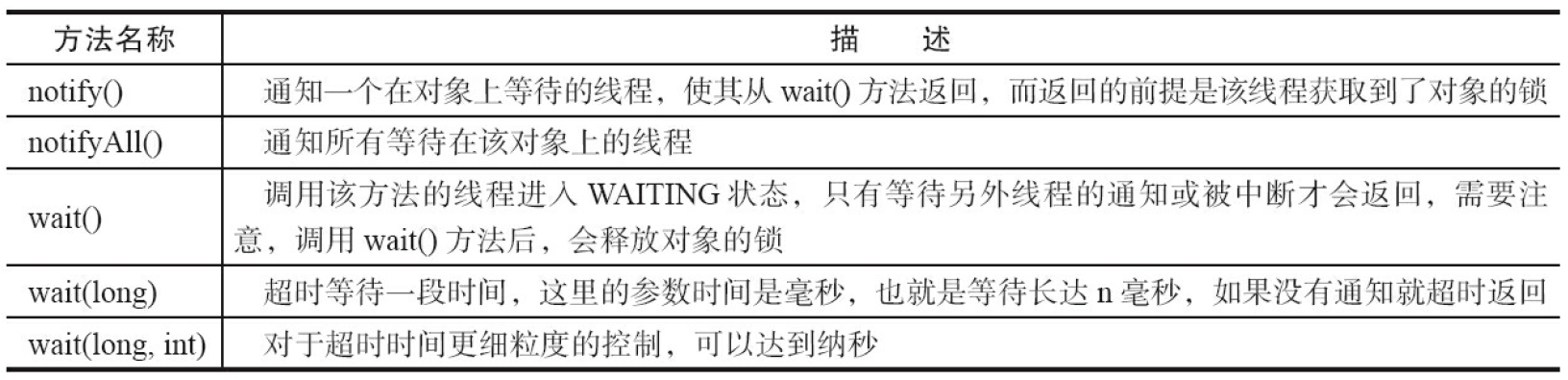
等待/通知的相关方法是任意Java对象都具备的,因为这些方法被定义在所有对象的超类java.lang.Object上,方法和描述如下图:
等待/通知机制,是指一个线程A调用了对象O的wait()方法进入等待状态,而另一个线程B调用了对象O的notify()或者notifyAll()方法,线程A收到通知后从对象O的wait()方法返回,进而执行后续操作。
上述两个线程通过对象O来完成交互,而对象上的wait()和notify/notifyAll()的关系就如同开关信号一样,用来完成等待方和通知方之间的交互工作。
下例中,创建了两个线程——WaitThread和NotifyThread,前者检查flag值是否为false,如果符合要求,进行后续操作,否则在lock上等待,后者在睡眠了一段时间后对lock进行通知,示例如下:
1 | public class WaitNotify { |
1 | Thread[WaitThread,5,main] flag is true. wait@ 08:32:25 |
上述3和4输出的顺序可能会互换,上述例子主要说明了调用wait()、notify()以及notifyAll()时需要注意的细节:
- 使用wait()、notify()和notifyAll()时需要先对调用对象加锁。
- 调用wait()方法后,线程状态由RUNNING变为WAITING,并将当前线程放置到对象的等待队列。
- notify()或notifyAll()方法调用后,等待线程依旧不会从wait()返回,需要调用notify()或notifAll()的线程释放锁之后,等待线程才有机会从wait()返回。
- notify()方法将等待队列中的一个等待线程从等待队列中移到同步队列中,而notifyAll()方法则是将等待队列中所有的线程全部移到同步队列,被移动的线程状态由WAITING变为BLOCKED。
- 从wait()方法返回的前提是获得了调用对象的锁。
上述细节中可以看到,等待/通知机制依托于同步机制,其目的就是确保等待线程从wait()方法返回时能够感知到通知线程对变量做出的修改。下图描述了上例的运行过程:
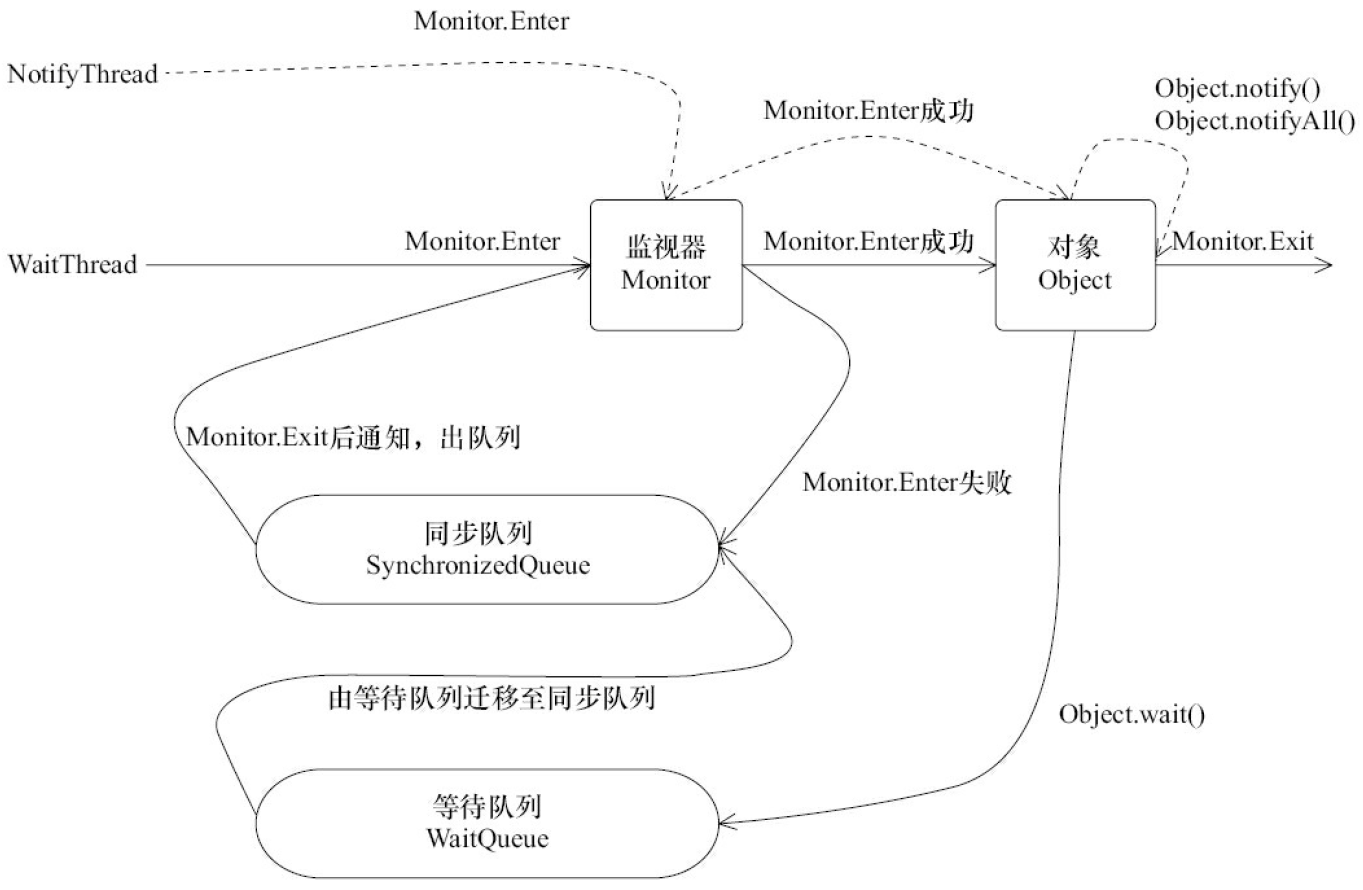
图中执行顺序:
- WaitThread首先获取了对象的锁,然后调用对象的wait()方法,从而放弃了锁并进入了对象的等待队列WaitQueue中,进入等待状态。
- 由于WaitThread释放了对象的锁,NotifyThread随后获取了对象的锁,并调用对象的notify()方法,将WaitThread从WaitQueue移到SynchronizedQueue中,此时WaitThread的状态变为阻塞状态。
- NotifyThread释放了锁之后,WaitThread再次获取到锁并从wait()方法返回继续执行。
等待/通知-经典范式
等待方遵循如下原则:
获取对象的锁。
如果条件不满足,那么调用对象的wait()方法,被通知后仍要检查条件。
条件满足则执行对应的逻辑。
对应的伪代码如下:
1
2
3
4
5
6synchronized(对象) {
while(条件不满足) {
对象.wait();
}
对应的处理逻辑
}
通知方遵循如下原则:
获得对象的锁。
改变条件。
通知所有等待在对象上的线程。
对应的伪代码如下:
1
2
3
4synchronized(对象) {
改变条件
对象.notifyAll();
}
管道输入/输出流
管道输入/输出流和普通的文件输入/输出流或者网络输入/输出流不同之处在于,它主要用于线程之间的数据传输,而传输的媒介为内存。
管道输入/输出流主要包括如下4种具体实现:PipedOutputStream、PipedInputStream、PipedReader和PipedWriter,前两种面向字节,后两种面向字符。
如下例子中,创建了printThread,它用来接受main线程的输入,任何main线程的输入均通过PipedWriter写入,而printThread在另一端通过PipedReader将内容读出并打印。
1 | public class Piped { |
运行该示例,输入一组字符串,可以看到被printThread进行了原样输出。
1 | Repeat my words. |
对于Piped类型的流,必须先要进行绑定,也就是调用connect()方法,如果没有将输入/输出流绑定起来,对于该流的访问将会抛出异常。
Thread.join()的使用
如果一个线程A执行了thread.join()语句,其含义是:当前线程A等待thread线程终止之后才从thread.join()返回。
线程Thread除了提供join()方法之外,还提供了join(long millis)和join(long millis,int nanos)两个具备超时特性的方法。这两个超时方法表示,如果线程thread在给定的超时时间里没有终止,那么将会从该超时方法中返回。
下例中,创建了10个线程,编号0~9,每个线程调用前一个线程的join()方法,也就是线程0结束了,线程1才能从join()方法中返回,而线程0需要等待main线程结束。
1 | public class Join { |
1 | main terminate. |
从上述输出可以看到,每个线程终止的前提是前驱线程的终止,每个线程等待前驱线程终止后,才从join()方法返回,这里涉及了等待/通知机制(等待前驱线程结束,接收前驱线程结束通知)。
以下是JDK中Thread.join()方法的源码:
1 | // 加锁当前线程对象 |
当线程终止时,会调用线程自身的notifyAll()方法,会通知所有等待在该线程对象上的线程。可以看到join()方法的逻辑结构与上述的等待/通知经典范式一致,即加锁、循环和处理逻辑3个步骤。
ThreadLocal的使用
ThreadLocal,即线程变量,是一个以ThreadLocal对象为键、任意对象为值的存储结构。这个结构被附带在线程上,也就是说一个线程可以根据一个ThreadLocal对象查询到绑定在这个线程上的一个值。
可以通过set(T)方法来设置一个值,在当前线程下再通过get()方法获取到原先设置的值。
在下例中,构建了一个常用的Profiler类,它具有begin()和end()两个方法,而end()方法返回从begin()方法调用开始到end()方法被调用时的时间差,单位是毫秒。
1 | public class Profiler { |
1 | Cost: 1002 mills |
Profiler可以被复用在方法调用耗时统计的功能上,在方法的入口前执行begin()方法,在方法调用后执行end()方法,好处是两个方法的调用不用在一个方法或者类中,比如在AOP(面向方面编程)中,可以在方法调用前的切入点执行begin()方法,而在方法调用后的切入点执行end()方法,这样依旧可以获得方法的执行耗时。