等待超时模式
使用场景:调用一个方法时等待一段时间(一般来说是给定一个时间段),如果该方法能够在给定的时间段之内得到结果,那么将结果立刻返回,反之,超时返回默认结果。
前面的章节介绍了等待/通知的经典范式,即加锁、条件循环和处理逻辑3个步骤,而这种范式无法做到超时等待。而超时等待的加入,只需要对经典范式做出非常小的改动,改动内容如下所示:
假设超时时间段是T,那么可以推断出在当前时间now+T之后就会超时。
定义如下变量:
- 等待持续时间:REMAINING=T。
- 超时时间:FUTURE=now+T。
这时仅需要wait(REMAINING)即可,在wait(REMAINING)返回之后会将执行:REMAINING=FUTURE–now。如果REMAINING小于等于0,表示已经超时,直接退出,否则将继续执行wait(REMAINING)。
上述等待超时模式的伪代码如下:
1 | // 对当前对象加锁 |
等待超时模式就是在等待/通知范式基础上增加了超时控制,这使得该模式相比原有范式更具有灵活性,因为即使方法执行时间过长,也不会“永久”阻塞调用者,而是会按照调用者的要求“按时”返回。
数据库连接池示例
我们使用等待超时模式来构造一个简单的数据库连接池,在示例中模拟从连接池中获取、使用和释放连接的过程,而客户端获取连接的过程被设定为等待超时的模式,也就是在1000毫秒内如果无法获取到可用连接,将会返回给客户端一个null。设定连接池的大小为10个,然后通过调节客户端的线程数来模拟无法获取连接的场景。
首先看一下连接池的定义。它通过构造函数初始化连接的最大上限,通过一个双向队列来维护连接,调用方需要先调用fetchConnection(long)方法来指定在多少毫秒内超时获取连接,当连接使用完成后,需要调用releaseConnection(Connection)方法将连接放回线程池,示例如下:
1 | public class ConnectionPool { |
由于java.sql.Connection是一个接口,最终的实现是由数据库驱动提供方来实现的,考虑到只是个示例,我们通过动态代理构造了一个Connection,该Connection的代理实现仅仅是在commit()方法调用时休眠100毫秒,示例如下:
1 | public class ConnectionDriver { |
下面通过一个示例来测试简易数据库连接池的工作情况,模拟客户端ConnectionRunner获取、使用、最后释放连接的过程,当它使用时连接将会增加获取到连接的数量,反之,将会增加未获取到连接的数量,示例如下:
1 | public class ConnectionPoolTest { |
上述示例中使用了CountDownLatch来确保ConnectionRunnerThread能够同时开始执行,并且在全部结束之后,才使main线程从等待状态中返回。
当前设定的场景是10个线程同时运行获取连接池(10个连接)中的连接,通过调节线程数量来观察未获取到连接的情况:线程数、总获取次数、获取到的数量、未获取到的数量以及未获取到的比率(实际输出可能与此表不同)。
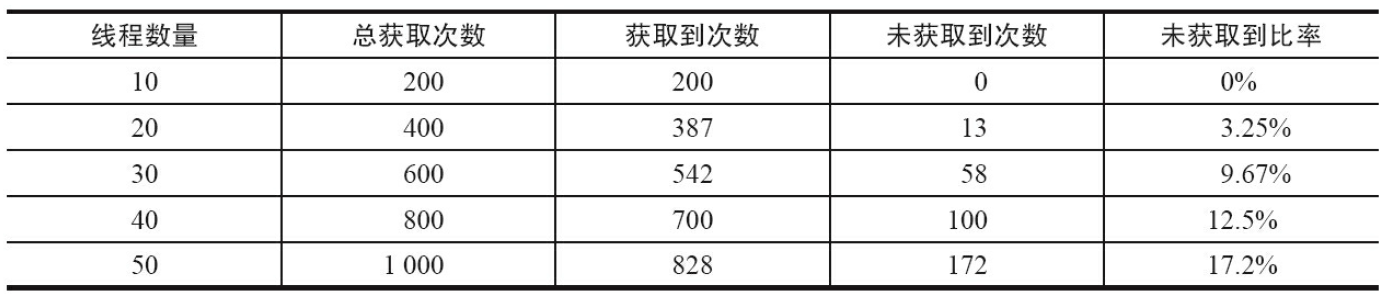
从表中的数据统计可以看出,在资源一定的情况下(连接池中的10个连接),随着客户端线程的逐步增加,客户端出现超时无法获取连接的比率不断升高。虽然客户端线程在这种超时获取的模式下会出现连接无法获取的情况,但是它能够保证客户端线程不会一直挂在连接获取的操作上,而是“按时”返回,并告知客户端连接获取出现问题,是系统的一种自我保护机制。数据库连接池的设计也可以复用到其他的资源获取的场景,针对昂贵资源(比如数据库连接)的获取都应该加以超时限制。
线程池技术及示例
应用场景:
对于服务端的程序,经常面对的是客户端传入的短小(执行时间短、工作内容较为单一)任务,需要服务端快速处理并返回结果。如果服务端每次接受到一个任务,创建一个线程,然后进行执行,这在原型阶段是个不错的选择。
但是面对成千上万的任务递交进服务器时,如果还是采用一个任务一个线程的方式,那么将会创建数以万记的线程,这会使操作系统频繁的进行线程上下文切换,无故增加系统的负载,而线程的创建和消亡都是需要耗费系统资源的,也无疑浪费了系统资源。
解决方案:
线程池技术能够很好地解决这个问题,它预先创建了若干数量的线程,并且不能由用户直接对线程的创建进行控制,在这个前提下重复使用固定或较为固定数目的线程来完成任务的执行。
这样做的好处是,一方面,消除了频繁创建和消亡线程的系统资源开销,另一方面,面对过量任务的提交能够平缓的劣化。
先看一个简单的线程池接口定义:
1 | public interface ThreadPool<Job extends Runnable> { |
客户端可以通过execute(Job)方法将Job提交入线程池执行,而客户端自身不用等待Job的执行完成。除了execute(Job)方法以外,线程池接口提供了增大/减少工作者线程以及关闭线程池的方法。这里工作者线程代表着一个重复执行Job的线程,而每个由客户端提交的Job都将进入到一个工作队列中等待工作者线程的处理。
以下是线程池接口的默认实现:
1 | public class DefaultThreadPool<Job extends Runnable> implements ThreadPool<Job> { |
当客户端调用execute(Job)方法时,会不断地向任务列表jobs中添加Job,而每个工作者线程会不断地从jobs上取出一个Job进行执行,当jobs为空时,工作者线程进入等待状态。
添加一个Job后,对工作队列jobs调用了其notify()方法,而不是notifyAll()方法,因为能够确定有工作者线程被唤醒,这时使用notify()方法将会比notifyAll()方法获得更小的开销(避免将等待队列中的线程全部移动到阻塞队列中)。
线程池的本质就是使用了一个线程安全的工作队列连接工作者线程和客户端线程,客户端线程将任务放入工作队列后便返回,而工作者线程则不断地从工作队列上取出工作并执行。当工作队列为空时,所有的工作者线程均等待在工作队列上,当有客户端提交了一个任务之后会通知任意一个工作者线程,随着大量的任务被提交,更多的工作者线程会被唤醒。