范围处理
定位连续值的范围
方法一:自关联
1 | SELECT v1.proj_id AS 工程号,v1.proj_start 开始日期,v1.proj_end 结束日期 |
方法二:分析函数 lead() over()
1 | SELECT proj_id AS 工程号,proj_start 开始日期,proj_end 结束日期 |
自关联需要扫描两次视图“V”,而使用分析函数只需要一次,大部分情况可以通过分析函数优化查询性能。
同组/分区中行间差值
方法一:自关联
1 | WITH x0 AS |
方法二:分析函数 lead() over()
1 | SELECT 登录名,登录时间, |
连续值范围的开始/结束
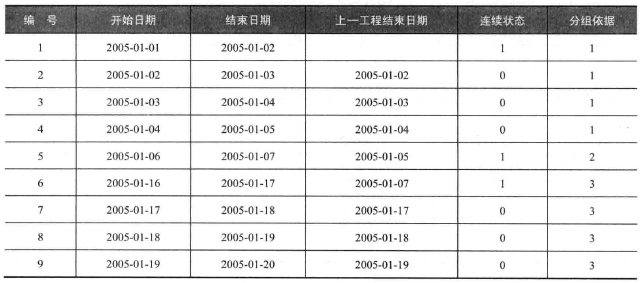
1 | SELECT 分组依据,MIN(开始日期) AS 开始日期,MAX(结束日期) AS 结束日期 FROM ( |
合并连续或重叠时间段
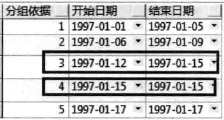
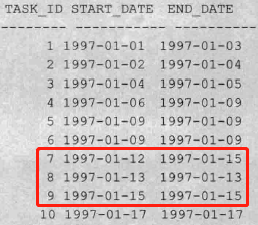
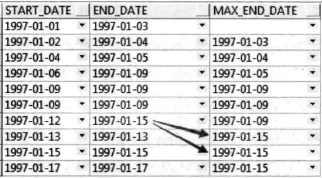
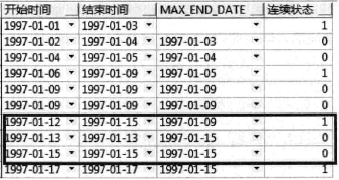
- 为处理重叠数据,与上一条数据判断时,需要“>=”
- “BETWEEN unbounded precedin AND 1 preceding” 就是一个 “BETWEEN … AND …” 子句,意思是“第一行到上一行”,此例分析函数就是 “ORDER BY start_date” 后 “第一行到上一行” 范围内的 “MAX(end_date)”。
1 | WITH |
高级查找
结果集分页
1 | /*方法一(推荐)*/ |
重新生成字段值
1 | CREATE TABLE hotel (floor_nbr, room_nbr) AS |
房间号不对,按 101、102、201、202 的形式重新生成:
1 | UPDATE hotel SET room_nbr = |
1 | # 可更新VIEW |
1 | /*方法一(子查询执行了5次,对hotel有5次全表扫描)*/ |
跳过表中 n 行
使用场景:对数据进行抽样,用求余函数 mod 隔 n 行返回数据。
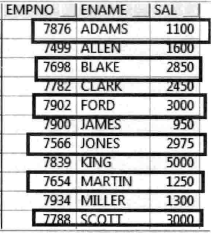
1 | SELECT empno, ename, sal, MOD(rn, 2) AS m FROM ( |
排列组合去重
数据环境模拟:
1 | CREATE TABLE TEST (id,t1,t2,t3) AS |
前三行中 t1、t2、t3 的数据组合是重复的(都是1、2、3),要求去重:
- 把 t1、t2、t3 这三列用列转行合并为一列。
- 用 listagg 函数对各组字符排序并合并。
- 执行常用去重语句。



1 | WITH |
找含最大/小值记录
1 | /*方法一(扫描三次,若object_id是索引则速度可能比分析函数快)*/ |
报表和数据仓库运算
行转列
- CASE WHEN END 编写和维护较麻烦,但适合的场景较多。
- Oracle11g新增的 PIVOT 函数编写维护简单,但有较大限制。(只是写法简单,实际上仍用的是 CASE WHEN 语句)
1 | SELECT job AS 工作, |
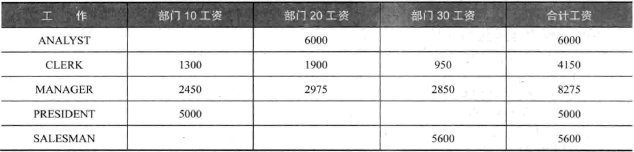
1 | SELECT * FROM ( |
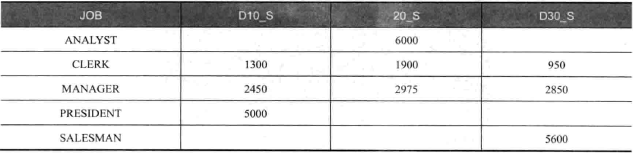
如果还要增加提成的返回列,用 PIVOT 则只需要增加一个设定即可:
1 | SELECT * FROM ( |
而用 CASE WHEN 要增加三行语句:
1 | SELECT job, |
PIVOT 一次只能按一个条件来完成“行转列”,如果同时把工作与部门转为列,并汇总为一行时,只能用 CASE WHEN。
1 | SELECT |

列转行

1 | /*以前用 UNION ALL来写*/ |

UPIVOT 同样有限制,如果同时有人次与工资合计要转换,就不能一次性完成,只有分别转换后再用 JOIN 连接:
1 | /*使用参数 INCLUDE NULLS,这样即使数据为空,也显示一行*/ |

是否有办法只用 UNPIVOT,而不用 JOIN 呢?
1 | SELECT deptno,人次,deptno2,工资 |
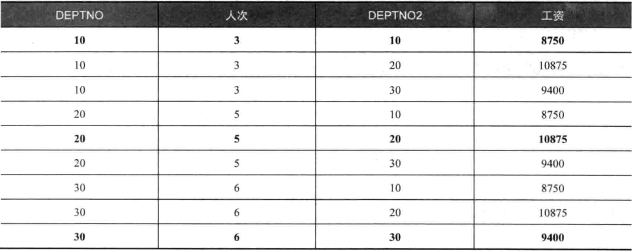
当使用两个 UNPIVOT 时,生成的结果是一个笛卡尔积,其中粗体字部分才是我们需要的。
上面的语句实际上是一个嵌套语句,前一个 UNPIVOT 结果出来后,再执行另一个 UNPIVOT:
1 | WITH x0 AS ( |
针对需要的数据,在上面的查询上加一个过滤即可:
1 | SELECT deptno AS 部门编码,人次,工资 |

结果集转置为一列
- 与 UNION ALL 一样,要合并的数据列类型必须相同,如下 TO_CHAR(SAL)。
- 如果不加 include nulls,将不会显示空行。
1 | SELECT EMPS FROM ( |
抑制结果集中重复值
1 | SELECT CASE |
利用“行转列”进行计算
使用场景:计算部门20与部门10及部门30之间的总工资差额。

1 | SELECT d10_sal,d20_sal,d30_sal, |

给数据分组
使用场景:为了方便打印,要求多行多列打印,如 emp.ename 类似下面显示:

1 | WITH |
对数据分组
使用场景:假期公司需要对雇员和经理分三组值班,用分析函数 ntile 来处理。
1 | SELECT ntile(3) over(ORDER BY empno) AS 组, |
计算简单的小计
使用场景:生成报表数据时加一个总合计,可以使用 ROLLUP 或 UNION ALL:
1 | SELECT deptno,SUM(sal) AS s_sal FROM emp GROUP BY ROLLUP(deptno); |
与 UNION ALL 对照实例:
1 | SELECT deptno AS 部门编码, |
相当于:
1 | SELECT deptno AS 部门编码, job AS 工作, mgr AS 主管, SUM(sal) as s_sal |
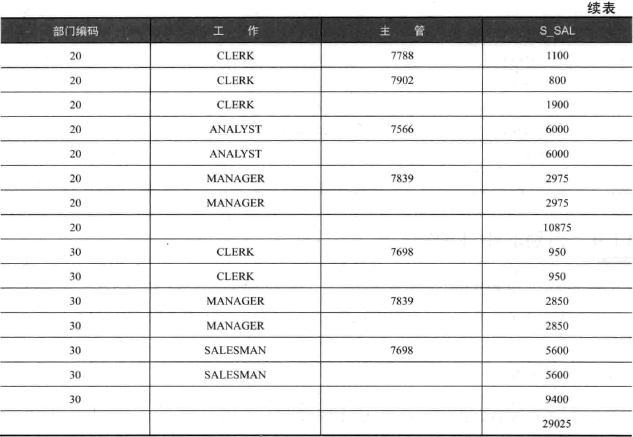
判别非小计的行
用 GROUPING 函数,参数只能是 group by 后的列名。
1 | /* 当列被汇总时,GROUPING 的返回值为1,否则为0 */ |
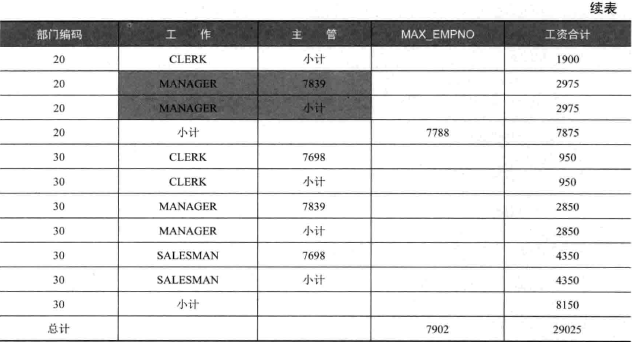
计算所有组合小计
grouping_id 函数 与 GROUPING 的对比:
1 | SELECT CASE GROUPING(deptno) || GROUPING(job) |
grouping 与 grouping_id 之间的关系及对应的 group by 对比如下:
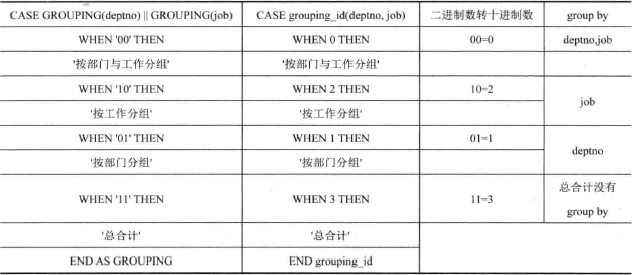
人员在工作间的分布
要求每种工作显示为一列,每位员工显示一行,员工与工作对应时显示1,否则为空:
1 | SELECT * FROM ( |
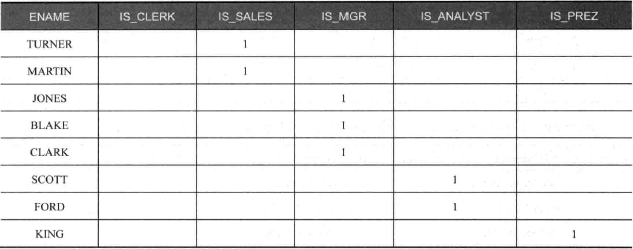
创建稀疏矩阵
在上例工种的分布基础上,增加在部门间的分布,由于未对数据进行汇总,所以仍可以用 PIVOT 来处理:
1 | SELECT * FROM ( |
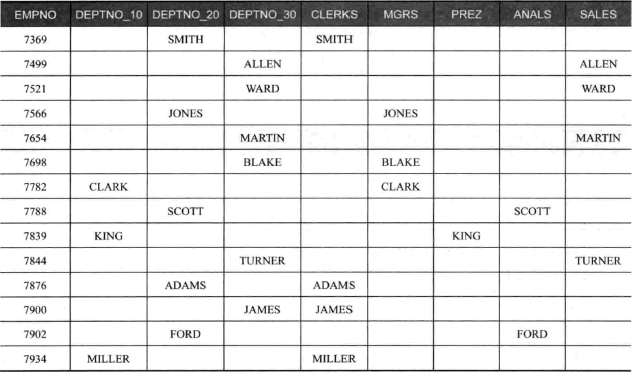
如果对数据有汇总,就不能用两个 PIVOT 的方式,因为这种查询实际相当于两个 PIVOT 的子句嵌套,应用 CASE WHEN 语句:
1 | SELECT |
若用 PIVOT:
1 | SELECT * FROM ( |

结果与 case when 的结果不一致,分析如下:
1 | /* 嵌套示例第一步,相当于 group by ename2,job */ |
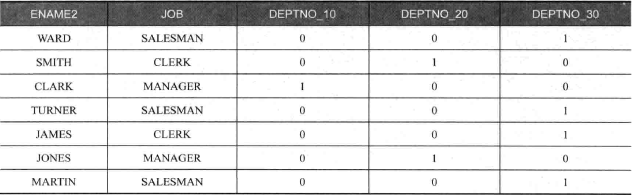
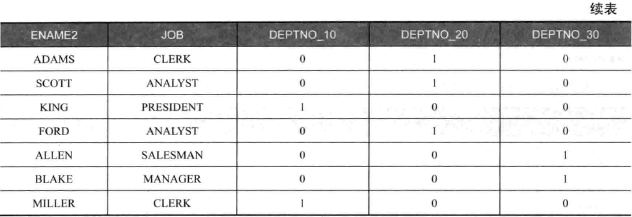
1 | /* 嵌套示例第二步,去除(ename2,job),相当于group by(deptno_10,deptno_20,deptno_30) */ |

不同组/分区的同时聚集
要求列出员工所在部门及职位的人数:
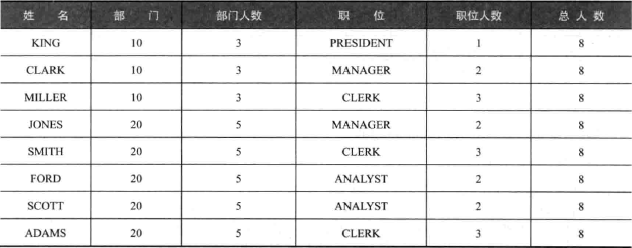
没用分析函数前,用自关联:
1 | /* 写法复杂,且对表emp访问四次 */ |
改用分析函数:
1 | SELECT ename 姓名, |
聚集移动范围的值
要求在员工明细表中显示之前90天(包含90)以内聘用人员的工资总和,以部门30为例,下面是标量及分析函数两种方式的示例:
1 | SELECT hiredate AS 聘用日期, |
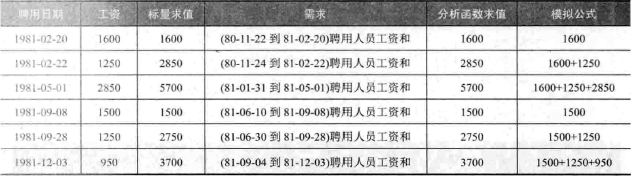
RANGE 关键字表示对相应字段做加减运算,所以只对日期与数值两类字段使用 RANGE 开窗。
对于日期 RANGE 开窗,默认单位是“天”,如果需求改为三个月内,可以使用 INTERVAL 来写明间隔单位:
1 | SELECT hiredate AS 聘用日期, |
按分钟开窗:
1 | /* 用 1/24/60 或 INTERVAL '1' minute 都可以 */ |
常用分析函数开窗
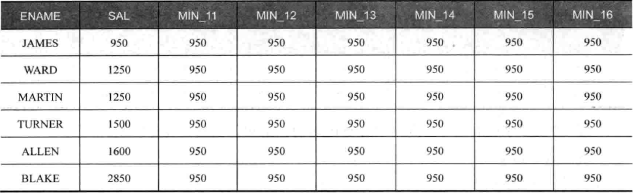
工资排序后取第一行到当前行范围内的最小值:
1 | SELECT ename,sal, |
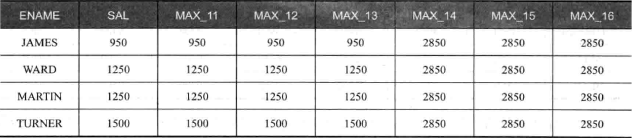
工资排序后取第一行到当前行范围内的最大值:
1 | SELECT ename,sal, |
工资排序后取第一行到当前行范围内的工资和,这里要注意区别:
1 | SELECT ename,sal, |
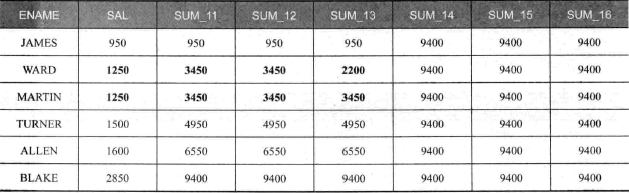
使用关键字“RANGE”时,第二行“SUM_11”、“SUM_12”对应的条件是“<=1250”,而1250有两个,所以:950+1250+1250=3450,而“SUM_13”:950+1250=2200。
前后都有限定条件:
1 | SELECT ENAME,SAL, |
listagg九九乘法表
1 | WITH |
分层查询
简单的树形查询
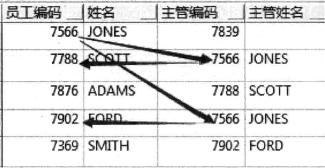
1 | SELECT empno AS 员工编码, |
- 起点:以 “START WITH empno = 7566” 为起点向下递归查询。
- 通过 “PRIOR” 取上一级信息,如上:主管姓名 (PRIOR ename)。
- CONNECT BY 子句列出来递归的条件:(上一级编码)等于本级主管编码。
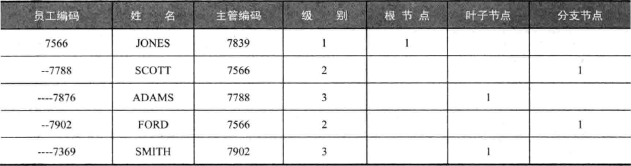
根/分支/叶子节点
- level 返回当前行所在的等级,根节点为1级,其下为2级…
- 若当前节点下没有其他节点,则 connect_by_isleaf 返回 1,否则返回 0
1 | SELECT lpad('-',(LEVEL-1)*2,'-') || empno AS 员工编码, |
sys_connect_by_path
根节点到当前节点的路径:
1 | SELECT empno AS 员工编码, |
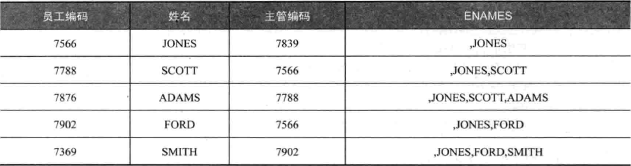
也可以代替 listagg 分析函数来合并字符串,因为 Oracle11.2 之前没有 listagg:
1 | WITH |
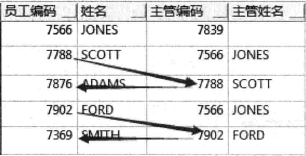
树形查询中的排序
树形查询里直接用 ORDER BY 排序,数据会乱,无法再看清上下级关系。
对于树形数据,应该只对同一分支下的数据排序,用专用关键字 “SIBLINGS”:
1 | SELECT lpad('-',(LEVEL-1)*2,'-') || empno AS 员工编码, |
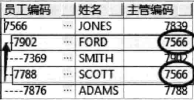
可以看到只对同分支7566下的7902、7788进行排序,没有影响树形结构。
树形查询中的WHERE
树形查询中的 WHERE 过滤对象是树形查询的结果,要过滤必须先用子查询嵌套一次,再进行树形查询:
1 | SELECT empno AS 员工编码, |
查询树形的一个分支
查询树形的一个分支不能用 WHERE,用 START WITH 指定分支的起点就可以:
1 | SELECT empno AS 员工编码, mgr AS 主管编码, ename AS 姓名, LEVEL AS 级别 |
剪去一个分支
要求减去 7698 开始的分支,同样不能在 WHERE 中加条件,因为树形查询递归是根据 (PRIOR empno)=mgr 进行的,如下即可:
1 | SELECT empno AS 员工编码, mgr AS 主管编码, ename AS 姓名, LEVEL AS 级别 |